Постановка задачи
Дело было вечером, делать было не чего. На носу стояла середина тёплого мая, и до приёмной компании в колледже, оставалось чуть больше месяца. Именно тогда в один из прекрасных вечеров ко мне в голову закралась идея. Реализовать парсинг данных со сканов абитуриентов, для повышения скорости заполнения заявления в online-формате. Идея заключалась в том, что абитуриент который собирается поступать в наш колледж, отдаёт документы сотруднику. Тот в свою очередь их сканирует, перекидывает в расшаренную папку по локальной сети на компьютере, за который садиться абитуриент. И на этом этапе сканы парсятся и данные автоматически подстраиваются в поля заявления.
Принцип сканирования документов
Из всего паспорта нам необходимо вытащить несколько значений, а именно:
- Кем выдан паспорт
- Дата выдачи
- Код подразделения
- Фамилия
- Имя и Отчество
- Дата рождения

Рисунок №1 – Пример паспорта для сканирования
Изначально, план был следующим:
- Определить на предложенном скане паспорта триггер
- На основе этого триггера нарезать изображение на части, в которых будет содержаться нужная информация
- Применить цветокоррекцию, устранение шумов для повышения чёткости изображения
- Отправить полученный результат в Tesseract OCR
Вооружившись технологиями, которые были реализованы в предыдущем проекте. Я принялся реализовывать предложенный алгоритм, ну а спустя неделю проклинал всё, что было связанно с этим проектом. Проблемы возникали по всюду и связаны со всем.
Появившиеся проблемы при парсинге данных
Первой проблемой стало то, что МФУ, которая стояла у приёмной компании не умела сканировать документы в формате JPG, PNG или других относящихся к фотографиям. Поэтому пришлось поискать что-то, что позволяет конвертировать PDF, в тот же JPG, PNG или TIFF.
Второе что хотелось бы отметить, то, что моей самописной библиотеке достаточно проблематично было определить триггер в низком разрешении. Если повышать разрешение, то процесс поиска занимает достаточно долгое время. Так-же тут присутствует нюанс, что библиотечка может и не найти триггер и что делать дальше, остаётся вопросом.
Третье. Найдя триггер и нарезав изображение на части, можно столкнуться с проблемой, что Tesseract OCR, не достаточно точно распознаёт изображения. Выходом из такой ситуации является создание списков, по которым какой-нибудь алгоритм будет проводить поиск на совпадение.
Используемые технологии для парсинга
Спустя ещё неделю, я наткнулся на интересную библиотечку: IronOcr
IronOCR расширяет Google Tesseract IronTesseract собственной библиотекой OCR C# с улучшенной стабильностью и более высокой точностью, чем бесплатная библиотека Tesseract.
Это библиотечка сделала всю грязную работу за меня. Не пришлось преобразовывать PDF в изображение, нарезать на куски код. Играться с цветокоррекцией. Достаточно просто дать ей PDF файл, и уже на основе него, библиотека выдаст данные.
Единственное, что меня не устраивало, то что библиотечка является платной. Но, можно получить бесплатный доступ на 30 дней, указав почту. Ну а временную почту никто не отменял 😂
Создаём новый проект, и устанавливаем библиотеку IronOcr. Она в свою очередь подтянет IronSoftware.Native.PdfModel и IronSoftware.System.Drawing. Кроме этого, устанавливаем IronOcr.Languages.Russian.

Рисунок №2 – Библиотеки для парсинга данных
Реализация парсинга данных со скана паспорта
Начнём с того, что создадим класс Passport, и объявим в нём следующие переменные:
// Кем выдан паспорт
public string Issued { get; set; }
// Дата выдачи
public string DateIssued { get; set; }
// Код выдачи
public string SubdivisionCode { get; set; }
// Серия и номер паспорта
public string SerialNumber { get; set; }
// Фамилия
public string FirstName { get; set; }
// Имя
public string LastName { get; set; }
// Отчество
public string SurName { get; set; }
// Пол
public string Sex { get; set; }
// Дата рождения
public string DateOfBirth { get; set; }
// Место рождения
public string PlaceOfBirth { get; set; }
// Путь до файла
public string Path { get; set; }
// Тип документа
public string Type = "passport";
// Правильность проверки даты выдачи
[JsonIgnore]
public bool IsCheckDateIssued = false;
// Правильность проверки даты рождения
[JsonIgnore]
public bool IsCheckDateOfBirth = false;
// Правильность проверки кода подразделения
[JsonIgnore]
public bool IsCheckSubdivisionCode = false;
// Правильность проверки серии и номера паспорта
[JsonIgnore]
public bool IsCheckSerialNumber = false;Далее создаём метод "ParsePDF(string Path)", который принимает путь до файла и прописываем следующий код:
// Сохраняем путь до файла
this.Path = Path;
// Создаём переменную, которая будет хранить результат
string sResultOce = "";
// Инициализируем библиотеку
var ocr = new IronTesseract();
// Устанавливаем язык
ocr.Language = OcrLanguage.Russian;
// Добавляем в исключение набор символов, которые нам не нужны
ocr.Configuration.BlackListCharacters = "—~`$#^*_}{]=[|\\@¢©«»°±·×‘’“”•…′″€™←↑→↓↔⇄⇒∅∼≅≈≠≤≥≪≫⌁⌘○◔◑◕●☐☑☒☕☮☯☺♡⚓✓✰";
// Разбиваем файл на байты
byte[] bytes = File.ReadAllBytes(Path);
// Создаём Input для чтения файла
using (var input = new OcrInput())
{
// Добавляем PDF, указывая набор байт
input.AddPdf(bytes);
// Удаляем цифровой шум
input.DeNoise();
// Поворачиваем изображение так, чтобы оно было правильно направлено вверх и ортогонально
input.Deskew();
// Начинам читать PDF
OcrResult result = ocr.Read(input);
// Весь резльтат записываем в переменную
sResultOce = result.Text;
}
// Выводим текст
Console.WriteLine(sResultOce);Идём тестировать, подаём на вход отсканированный паспорт абитуриента, и смотрим, что у нас получилось на выходе.
// Инициализируем класс паспорта
Classes.Passport ScanPassport = new Passport();
// Вызываем сканирование паспорта
ScanPassport.ParsePDF(@"A:\Doki\doc00362720230518111102.pdf");Результат сканирования:
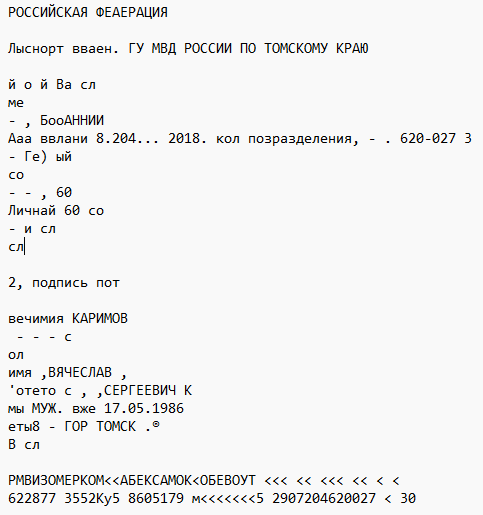
Рисунок №3 – Результат парсинга данных
Как видно, данные с PDF файла мы получили. Теперь их нужно распарсить, понять где находится фамилия, где находится имя, и т.д.
Сразу же скажу что буду использовать метод Левенштейна. Метод Левенштейна — метрика, позволяющая определить «схожесть» двух строк — минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую.
В первую очередь определим кем был выдан паспорт. Для этого весь полученный результат разбиваем на строки:
// Разделяем весь результат чтобы работать со строками
string[] SplitResult = sResultOce.Split(new string[1] { "\r\n" }, StringSplitOptions.None);Далее при помощи алгоритма Левенштейна, находим наименьшее совпадение:
#region Паспорт выдан
// Задаём индекс который будет отвечать за наименьшее совпадение со строкой
int IndexMin = SplitResult.Length;
// Задаём индекс совпадения в справочнике
int IndexLevenshtein = 0;
// Указываем совпадение
int Min = 1000000000;
// Перебираем строки
for (int iRow = 0; iRow < SplitResult.Length; iRow++)
{
// Запоминаем результат
string Row = SplitResult[iRow];
// Если результат не равен пустоте
if (Row != "")
{
// Удаляем лишние слова которые могут спарсится
Row = SplitResult[iRow].Replace("Паспорт вндан", "");
Row = Row.Replace("Паспорт задан", "");
Row = Row.Replace(".", "");
Row = Row.Replace("-", "");
// Удаляем двойные пробелы
Row = DoubleSpace(Row);
// Перебираем справочник
for (int iIssued = 0; iIssued < MainWindow.DictionariesPasport.Issueds.Count; iIssued++)
{
// Определеяем совпадение
int iLevenshtein = Levenshtein(Row, MainWindow.DictionariesPasport.Issueds[iIssued]);
// Если совпадение с записью в справочнике меньше чем мы запомнили
if (iLevenshtein < Min)
{
// Запоминаем совпадение в справочнике
IndexLevenshtein = iIssued;
// Запоминаем наименьший результат
Min = iLevenshtein;
// Запоминаем индекс строки на которой был результат
IndexMin = iRow;
}
}
}
}
// Выводим надписи
Debug.WriteLine("Строка с наименьшим совпадением: " + SplitResult[IndexMin]);
Debug.WriteLine("!Определено. Паспорт выдан: " + MainWindow.DictionariesPasport.Issueds[IndexLevenshtein]);
// Запоминаем кем был выдан паспорт по наименьшому совпадению
this.Issued = MainWindow.DictionariesPasport.Issueds[IndexLevenshtein];
#endregionРезультат на лицо:
Строка с наименьшим совпадением: Лыснорт вваен. ГУ МВД РОССИИ ПО ТОМСКОМУ КРАЮ
!Определено. Паспорт выдан: ГУ МВД РОССИИ ПО ТОМСКОМУ КРАЮАналогичным способом получаем все остальные данные. И по итогу, результат имеет следующий вид:
!Определено. Паспорт выдан: ГУ МВД РОССИИ ПО ТОМСКОМУ КРАЮ
!Определено. код подразделения: 620-027
Дата: 17.05.1986
!Определено. Фамилия: КАРИМОВ
!Определено. Имя: ВЯЧЕСЛАВ
!Определено. Отчетсво: СЕРГЕЕВИЧ
!Определено. Пол: МУЖ
!Определено. Место рождения: Г. ТОМСК
!Скорректировано. Серия и номер паспорта: 62 25 877355Кроме всего этого, в программе присутствует дополнительная проверка данных, которая сверяет полученные данные в процессе парсинга, с данными которые находятся в самом низу скана.
Ссылочка на проект: https://github.com/Alexashchka/Scan-Russin-Passport